サービス







noindex,nofollowとは?違いと効果的な使い方とは

SEOに携わっている方ならばnoindex,nofollowと聞いたことがある方も多いのではないでしょうか?
本記事ではnoindex,nofollowの意味から使い方までを解説していきます。
クロール・インデックスの最適化を目指す大規模サイトのSEO担当者の方はもちろん、小規模なブログやメディアを運営している方まで、理解しておくべき内容ですので、ぜひ参考にしてみてください。
noindex,nofollow以外のクロール・インデックス最適化を促す施策については下記の記事もご覧ください。
あわせて読みたい


SEOの内部対策とは|外部対策との違いや方法を解説
SEOで売上アップを目指すためには、競合記事よりも高い検索順位を獲得する必要があります。 SEO対策には「内部対策」と「外部対策」の2種類があり、どちらも検索上位を…
無料ホワイトペーパー「SEO対策の教科書【完全版】」はこちら>>

Webinar
無料ウェビナーのお知らせ

内容
- 成果に繋がるSEOプロジェクトの条件とは?
- LANYの事例で学ぶSEOプロジェクトの正しい進め方
- Q&A
開催日時
①2025年7月1日(火)12:00〜13:00
②2025年7月10日(木)12:00〜13:00
※いずれかの日程でお申し込みください。
おすすめの対象者の方
- デジタルマーケティングに注力したいと考えているBtoB企業の方
- SEOに取り組んでいるが思うように成果が出ないと感じているマーケティング担当の方
- 成果が出ているSEOプロジェクトの型や事例を知りたい方
目次
noindexとは?
noindexとは、検索エンジンに対してインデックスをしない、または既にインデックス登録されているページをインデックスから削除する指示のことを指します。
canonicalともよく並列で扱われますが、canonicalはURLを正規化するために利用するのに対して、noindexはインデックスに登録しない、または削除という使い方です。
つまり、canonicalは「インデックスは削除せず、正規化(評価統合)だけを実施」するのに対し、noindexは「正規化(評価統合)はせず、インデックスのみ削除」します。
目的に応じて使い分ける必要がありますので、本記事でnoindexの利用用途をきちんと押さえていってください。
なぜnoindexを使うのか?
noindexを使うシーンとしては、下記のようなケースがあります。
- 低品質ページをインデックスから削除し、サイトの品質を向上させるため
- 非正規ページをインデックス から削除し、重複ページを避けるため
低品質コンテンツの削除施策の際に、物理削除(ステータスコード404)ではなく、論理削除(noindex対応)をすることが多いです。
何故なら、noindex対応であれば、検索結果経由には表出されなくなるものの、サイト内回遊ではユーザーが閲覧できる状態になり、検索エンジンに評価されないコンテンツだとしてもユーザーに評価されるものである場合に残すことができるためです。
ただ、むやみやたらにnoindexをすればいいというわけではなく、明確な目的を持って設定することが重要ですので、サイトの目的に対してnoindex対応が適切かどうかをきちんと判断した上で実施するようにしましょう。
noindexの設定方法
noindexの設定方法は、大きく2種類に分かれます。
①meta robotsタグで設定するケース
noindexを設定したいページのheadセクションに下記のように記述することで、設定したページをnoindexにすることができます。
ページ単位で細かく設定できるので、どのページが重複・低品質ページなのかをはっきりさせた上で設定することが求められます。
<!DOCTYPE html>
<html><head>
<meta name="robots" content="noindex" />
(…)
</head>
<body>(…)</body>
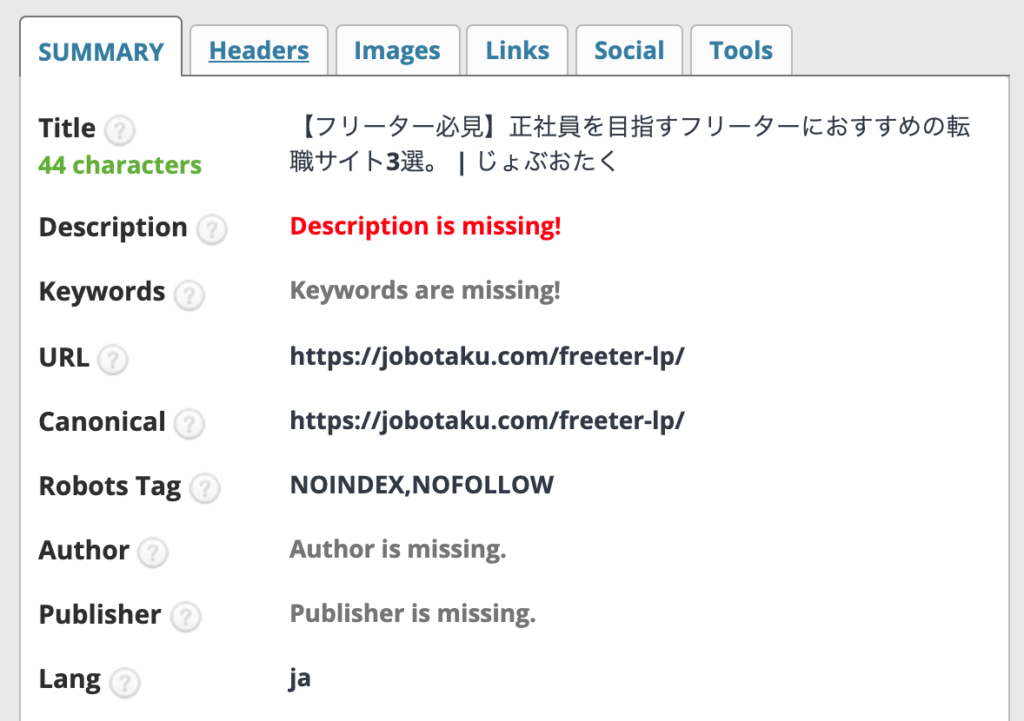
</html>実際にとあるページにnoindexが記載されているかどうかを確認するには、たとえばGoogle Chromeのディベロッパーツールで検証モードを開き、”noindex” と検索してあげましょう。
もしくは『SEO META in 1 CLICK』というChromeの拡張機能を利用すると、下記のようにワンクリックで確認できるようになるため、おすすめです。
②HTTPヘッダーのX-robots-Tagで設定するケース
httpd.confファイルや.htaccessファイルで設定することができます。
また、正規表現をサポートしているため、柔軟な設定が可能です。
例えば、jpg,jpeg,png,gifなどのファイルをまとめてnoindex設定したいような場合に、下記のような記述をすることでまとめて該当するファイルに対してnoindex指示を出すことできます。
 SEOおたく
SEOおたく正規表現を誤って指定してしまうと、予期しないページまでnoindexしてしまい、結果的にトラフィックが大幅に減ってしまうなどのミスも発生しがちです。
扱う際には事前にGoogle Analyticsで正規表現を記述することで意図したページだけ抽出できているか確認しておくと良いと思います。
Apacheサーバーの場合
<Files ~ "\.(png|jpe?g|gif)$">
Header set X-Robots-Tag "noindex"
</Files>
参考:Google検索セントラル X-robots-Tag HTTPヘッダーの使用
noindexが効かない?
よく聞くケースとして、noindexを設定したのに検索結果から削除されない、ということを聞きます。
noindexは設定したらすぐに検索結果から削除されるわけではありません。
noindexタグを設定後、googlebotが該当ページへクローリングさせてnoindexが付与されていることをgooglebotが認識し、googleのデータベースに持ち帰って情報が更新されると初めて検索結果から削除されます。
また、サイト内部/サイト外部から多くのリンクを獲得しているページをnoindexしても、検索結果に出続けるケースがあるともドキュメントには記述もあります。
そもそも、内部リンク外部リンクが多く集まるページ≒重要なページであるケースが多いと思われるので、そういったページをnoindexするケースはほとんどないとは思いますが、注意が必要です。
なんらかの事情で、公開してしまったwebページを検索結果から急いで削除したい場合、URL削除ツールを利用するか、HTTPステータスコードを変更する等の対応のほうが良いケースもあります。

Google for Developers

noindex を使用してコンテンツをインデックスから除外する | Google 検索セントラル | Documentation | …
noindex(ノーインデックス)とは、ページを Google のインデックスから除外し、検索結果に表示されないようにするためのメタタグです。noindex の実装方法について説明し…
noindexを貼り続けるとどうなるのか
noindexを長期間貼っている、または貼る予定がある場合に、起こりうる事象について事前に認識しておくことが重要です。
ここでは、あまりご存じない方もいるかもしれませんが、長期間noindexを貼り続けた場合に起こりうるケースについて解説します。
クロールをブロックするわけではない
こちらもよく誤解されがちな問題ですが、noindexを設定する≠googlebotのクロールをブロックする、ということです。
つまり、noindexを設定したからと言ってgooglebotのクロールがその後来なくなるわけではなく、クロールの頻度は落ちますが、クロールはき続けます。
クロールバジェットを削減したいのであれば、noindexでインデックスを制御後にrobots.txtのDisallowでクロールをブロックする必要があります。
noindexにしたページはその後インデックス再登録されにくい
一度noindexにしたページは、noindexを外した後にインデックス再登録が可能となりますが、過去経験則上インデックス再登録までのリードタイムは長くなってしまいます。
インデックス再登録する可能性があるページに対しては、noindexを設定するのではなく、ステータスコード404を返して、そのページが一時的に利用不可である旨をgoogleに伝達する方法がベターかと思います。
急ぎ再登録したい場合には、URL検査ツールからインデックス登録リクエストを送信し、googlebotの回遊ならびにインデックス再登録を待つ必要があります。
noindexにし続けるとnofollow属性も付与される
noindexにすると、該当のページをインデックス登録はしないが、ページ内のリンクは辿る、という状況になります。
後述するnofollow属性も合わせて指示すると、インデックス登録もしないし、ページ内のリンクも辿らないという指示になります。
長期間noindexにし続けると、googleはnofollowの属性も付与して該当ページを扱うという発言もあるため、ページ内のリンクを辿らせる必要があるならば、発リンク先をsitemap.xmlに含めるなど、何かしらの工夫が求められます。
参照:Google: Long Term Noindex Will Lead To Nofollow On Links
SEOについてお悩みの方へ
LANYのSEOコンサルティング
サービス概要資料
LANYのサービス導入事例
 NTTドコモ 様
NTTドコモ 様株式会社NTTドコモ 様
(ご利用サービス:SEOコンサルティング)
LANYさんとの取り組み開始直後から綺麗な右肩上がりでクロール数・インデックス数が共に伸びており、インデックス数は開始前と比べて130%程度増加しました。
▶︎SEOコンサルティング事例詳細を見る
nofollowとは?
nofollowとは、設定することでgooglebotに対してリンクを辿らせないという効果があります。
noindexのようにmetaタグとして設定できることに加え、aタグのリンクに対しても設定することが可能です。
多くの場合は後者のケースで利用されることが多いですが、ここでは前者の話も交えて解説していきます。
noindexとnofollowの違い
どちらのタグもmetaのcontent属性に設定できる点は共通しています。
異なる点は、noindexは検索エンジンに対してindex登録はさせないが、ページ内のリンクは辿っても良いという指示に対してnofollowだけを設定すると、インデックス登録はさせてよいが、ページ内のリンクは辿らない、またはnofollowが付与されたページ内外に向けたリンクは辿らない、という指示になります。
nofollow/follow属性の使い方
meta robots でのfollowの明示
使い方としては、例えば検索結果一覧ページの2ページ目以降はnoindexにしたい、ただし詳細ページへの導線としては使いたいというときには
meta robot noindex,follow
を指示するケースがあります。
これは前段の、noindexを長く使用し続けるとnofollow属性も付与される仕組みがあるため、明示的にfollow属性を付与しておくことでサイト内のクローラー導線として活用したいという意思をgoogleに伝えています。
SEOおたくこれは、データベース型サイトの一覧ページで扱われることが多いでしょう。
ただし、GoogleのGary氏はmeta robotsでのnofollowはヒントとして扱う旨の発言をしていることから、followを入れていても絶対ではない可能性はあるかもしれません。
meta robotsでのnofollowの明示
たとえば、発リンク先が低品質なページである、またはすべて広告リンクのみが貼られている、リンク先のサイト/ページと関連付けさせたくないようなケースではnofollow属性を明示することが可能です。
ただしそのようなページの場合、そもそもインデックスさせる価値があるページなのかどうかも併せて検討できると良いように思います。
link rel nofollow
皆さんが一般的に認識されている使い方で、aタグのような個別リンクに対して、設定したリンクをクロールさせない、という指示になります。
また、2019年9月に、nofollowの扱いを絶対的なものではなくヒントとして扱うように処理が変更されました。
進化する「nofollow」–リンクの性質を識別する新しい方法
nofollowは指定したリンク先にリンクジュースを渡さないようにするため、サイト外への発リンクには全てnofollowを設置してしまおう、という考え方が一般化しておりましたが、これは本来のGoogleの意図する用途ではありません。
Googleは常により良い検索結果を返すことを指名としているため、リンクから得られる情報が従来通り命令のままだとその妨げになると判断し、あくまでヒントとして扱うというように変更したものと考えられます。
rel sponsored
2020年9月から新しい属性の1つとして導入されました。
広告や有料プレースメントに対して指定できる属性となっており、特にアフィリエイトリンクに対してgoogleが使用するようにと推奨している属性になります。
すでに設定しているnofollowと併記することが可能ですが、meta robotsタグでの利用はできません。
rel ugc
rel sponseredと同タイミングで導入されたugc属性です。ugc=user generated contentの略称で、口コミなどのユーザーが作成したコンテンツのリンクに対して指定できる属性となっています。
こちらもすでに設定しているnofollowと併記することが可能ですが、meta robotsタグでの利用はできません。
| 検索エンジン種別 | rel=”nofollow” | rel=”sponsored” | rel=”ugc” |
| googlebot | 〇meta robotsで使用可能※ただしヒントとして扱う | 〇meta robotsでの使用不可nofollwと組み合わせ可能ヒントとして扱う | 〇meta robotsでの使用不可nofollowと組み合わせ可能ヒントとして扱う |
| 他検索エンジン | 〇 | × | × |
記事執筆時点での状況を整理すると上記の通りです。
今後他検索エンジンにも対応する可能性はあるかもしれませんし、従来通りかもしれません。
SEOについてお悩みの方へ
LANYのSEOコンサルティング
- サービス・料金プランの詳細
- 提供内容のアウトプットイメージ
- SEOコンサルティングの事例

LANYのサービス導入事例
NTTドコモ 様株式会社NTTドコモ 様
(ご利用サービス:SEOコンサルティング)
LANYさんとの取り組み開始直後から綺麗な右肩上がりでクロール数・インデックス数が共に伸びており、インデックス数は開始前と比べて130%程度増加しました。
▶︎SEOコンサルティング事例詳細を見る
nofollowをugcやsponsoredに変える必要があるか?
google検索セントラル上では、既に入っているものに関してはまったく修正する必要はないと発言しています。
今後新規で記事やコンテンツを作成していく場合にはこれらの属性も考慮して作成することがベターでしょう。
Google側の視点からすれば、たくさんこれらの属性をウェブマスター側に使ってもらうことでGoogleの機械学習が進み、よりよい処理をできるようになるはずです。
現時点では、nofollowを適切なリンク属性に変えるべきメリットが見え切れてはおりませんが、中長期的なSEO改善を目指す場合には、ポリシーとしてそれぞれ適切に利用するようにしてみても良いかと思います。
noindex nofollowのまとめ
本記事ではnoindexとnofollowについて解説しました。
少しニッチな説明も交えましたが、Googleが言っていることを正しく解釈すること、実データから得られるファクトを見出すこと、ともに重要だと思います。
前者については多くのwebサイトやGoogle公式情報から簡単に情報を入手することはできますが、後者のファクト部分については実際のご自身のサイトと向き合っていくことが一番の近道だと思います。
LANYでは今後も定量的なファクトから得られた示唆も交えながら、皆様のためになるような情報を発信していけたらと思います。
ebook
【無料お役立ち資料】
SEO対策の教科書【完全版】

- スライド179枚
- 2時間の無料動画
\SEO担当者のあなたへ/
無料のSEOメールマガジン
デジタルマーケティングの課題解決に役立つ情報をお届けする
購読者数4,200人超えの人気メルマガ
- SEOの最新情報をキャッチアップできる
- SEOの成功事例や限定Tipsが届く
- 限定ウェビナーの情報がいち早く届く
SEO初心者や企業のSEO担当者の方まで役立つ内容のためぜひご登録ください!
関連記事
-
【2024年最新】Google検索のアルゴリズムと最新アップデートの概要を紹介Google検索のアルゴリズムとは、あるキーワードの検索順位を決定するときのルールです。 アルゴリズムのアップデートは、自社コンテンツの表示順位や検索流入に大きな影...
-
【速報】2024年3月Googleコアアルゴリズムアップデートが到来2024年3月6日に、Googleコアアルゴリズムアップデートのロールアウトが、GoogleのX公式アカウントより告知されました。 https://twitter.com/googlesearchc/status/1765...
-
Googleサーチコンソールの使い方|SEO改善の方法や具体的な成功事例SEOをする上で欠かせないツールが、Googleサーチコンソールです。 Googleサーチコンソールは「サイトのアクセス前のデータを取得できるツール」です。 Googleサーチコン...
-
サービスサイトで取り組むべきSEO|ポイントや注意点を解説サービスサイトからの集客数が伸びない、検索してもなかなか上位表示されないと悩んでいる方のなかには、改善したくても具体的な解決策がわからないという方も多いので...
-
SEOで2つ(複数)のキーワードを同じ記事で対策するか、別の記事で対策するか記事を書く時には対策キーワードを決めますが、よくあるのが「似ている2つのキーワードを1記事で対策するか2記事で対策するか」という悩み。 異なるキーワードだからと...
-
ロングテールキーワードとは?SEOにおいて重要な理由と選び方をツール別に解説SEO対策をする上で、キーワード選定は非常に重要です。 キーワード選定の精度によって、SEOの成果が決まると言っても過言ではありません。 キーワード選定の手法は多種...
-
1月12日完了|helpful content update(ヘルプフルコンテンツアップデート)の傾向と対策2022年12月5日にhelpful content updateのグローバル展開を発表しました。そして、2023年1月12日ロールアウトされたことが確認できました。 https://developers.google....
-
小規模SEOプレイヤーが勝つためには「頑張る場所をズラすこと」が重要SEOはシェアの奪い合いであり、多くのプレイヤーが参入している領域であればあるほど勝つための難易度は高くなります。 昨今では、最先端のSEO情報にも非常にアクセスし...







